This post will describe more concepts in Hive
Partitions:
1. How data is stored in HDFS
2. Grouping databases on some column
3. Can have one or more columns.
How partitioning will work?
Usually tables data will be stored in HDFS like below
/user/hive/warehouse//
/user/hive/warehouse//
/user/hive/warehouse//
/user/hive/warehouse//
If we know how data is coming from source of the file , If we implement filter condition using where condition
Then we will do the partitioning for the given data like below
/user/hive/warehouse///month-jan/ /user/hive/warehouse///month-feb/ /user/hive/warehouse///month-march/ /user/hive/warehouse///month-april/ Bucketing is used to improve the performance. What do we mean by Partitions? 1. Partitions means dividing a table into a coarse grained parts based on the value of a particular column such as date. 2. This make it faster to do queries on slices of the data. 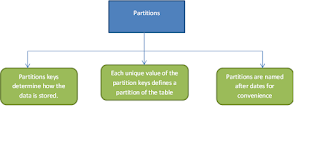
Buckets or Clusters 1. Partitions divided further into buckets bases on some other column 2. Use for data sampling. Buckets: 1. Buckets give more extra structure to the data , that may be used for efficient queries. 2. A Join of two tables that are bucketed on the same columns – including the join column can be implemented as a Map Side Join.(Depending on hash value.) 3. Bucketing by user id means, we can easily and quickly evaluate a user based query by running it on a randomized sample of the total set of users. Now we will see how to work partition and bucketing 1. First create a table called transaction_records 2. For that, first create a database called retail Command: to create database Partitions:
1. How data is stored in HDFS
2. Grouping databases on some column
3. Can have one or more columns.
How partitioning will work?
Usually tables data will be stored in HDFS like below
/user/hive/warehouse/
/user/hive/warehouse/
/user/hive/warehouse/
/user/hive/warehouse/
If we know how data is coming from source of the file , If we implement filter condition using where condition
Then we will do the partitioning for the given data like below
/user/hive/warehouse/

Hive> create database retail;Command: to use database
Hive> use retail;Now we need to create a table.
Hive> create table transaction_records(txnno INT,txndate STRING,custno INT,amount DOUBLE,category STRING, product STRING,City STRING,State String,Spendby String ) row format delimited fields terminated by ‘,’ stored as textfile;How to load data into table?
Hive> LOAD DATA LOCAL INPATH ‘/usr/local/hive_demo/transaction/’ INTO TABLE transaction_records; Hive> select count(*) from transaction_records;We can try different queries as like SQL. Ex: Aggregation: 1. select category,sum(amount) from transaction_records group by category; Grouping: 2. distinct(select (DISTINCT category ) from transaction_records; How to copy table data into another table or file or HDFS? 1. Insert output into another table
Insert overwite table results(select * from transaction_records); Create table results as select * from transaction_records;2. Insert Output into local file.
Insert overwrite local directory ‘results’ select * from transaction_records;3. Inserting output into HDFS
Insert overwrite directory ‘/results’ select * from transaction_records;How to write all queries in a single script file and execute the same? Hive Scripts are used to execute a set of Hive Commands collectively. This helps in reducing the time and effort invested in writing and executing each command manually. Hive support scripting from Hive 0.10.0 and above versions. Name file as hive_script.hql and place it where ever you like( here I keeping inside /usr/local/hive_demo/
use retail; create table transaction_records_script(txnno INT,txndate STRING,custno INT,amount DOUBLE,category STRING, product STRING,City STRING,State String,Spendby String ) row format delimited fields terminated by ‘,’ stored as textfile; LOAD DATA LOCAL INPATH ‘/usr/local/hive_demo/transaction/’ INTO TABLE transaction_records_ script; Select count(*) from transaction_records_ script; select category,sum(amount) from transaction_records group by category;How to Run the hive script file. hive -f hive_script.hql OR hive -f hive_script.sql (if we named our script file as .sql then we can use this.) Hive Joins (table joining) Create a script to create tables called employee and email Before creating script we need to create 2 files(emp.txt,email.txt) and need to filled with data /usr/local/hive_demo/emp.txt
siva,56000,bangalore raju,67000,chennai arjun,25000,mumbai sweety,54000,pune/usr/local/hive_demo/email.txt
siva,siva@gmail.com raju,raju@yahoo.com arjun,arjun@aol.com sweety,sweety@rediff.com jatin,jatin@gmail.com sneha,sneha@hotmail.comCreate a script to work with joining tables demo
Use retail; Create table employee(name string,salary float,city string) row format delimited fields terminated by ‘,’ ; Load data local INPATH ‘/usr/local/hive_demo/emp.txt’ into table employee; Create table email(name string,email string) row format delimited fields terminated by ‘,’; Load data local inpath ‘/usr/local/hive_demo/email.txt’ into table email;
 After creating the script now we need to run the hive_join_demo.hql file.
hive -f hive_join_demo.hql
Now we will work with joins: Inner join
After creating the script now we need to run the hive_join_demo.hql file.
hive -f hive_join_demo.hql
Now we will work with joins: Inner join Hive> select a.name,a.city,a.salary,b.email_id from employee a join email b on a.name=b.name;It will display name,city ,salary and email id where matching condition between two tables; Left outer join
Hive> select a.name,a.city,a.salary,b.email_id from employee a LEFT OUTER join email b on a.name=b.name;It will display all the records from first table and matching records from second table. Right outer join
Hive>select a.name,a.city,a.salary,b.email_id from employee a RIGHT OUTER join email b on a.name=b.name;It will display all the records from second table and matching records from first table.
This is how we will work with hive sql joins.
Thank you very much for viewing this.


















